


A couple weeks ago, we did a head-to-head Jeopardy! benchmarking between OpenAI (o1-mini) and the newly released DeepSeek R1 (32B and 70B).
Today, let's expand the benchmarking arena to include Claude, Llama, and AWS Nova models.
Testing so many models at once can be tedious – we'd need to set up API credentials and integrate with different SDKs from different providers.
But AWS Bedrock makes it super easy. Released in September 2023, Bedrock quickly became a popular choice for leveraging the power of generative AI. Through Bedrock, we can access a wide range of models, both closed-source models like the Anthropic Claude series, and open-weight models like Llama, Mistral, and most recently, DeepSeek.
For developers already building on AWS, integration with Bedrock is seamless – you would use exactly the same boto3 SDK to access Bedrock models and platform, with all AWS security and management features built in. Anyone building large-scale AI solutions should seriously consider Bedrock.
So AWS Bedrock is the topic of today's one day tour. We will use Bedrock to test several models all in one go:
- Claude Sonnet 3.5 v2 (released Oct. 2024)
- Claude Haiku 3.5 (released Oct. 2024)
- Llama 3.3 70B (released Dec. 2024)
- Llama 3.2 3B (released Sep. 2024)
- Llama 3.2 1B (released Sep. 2024)
- AWS Nova Pro (released Dec. 2024)
- AWS Nova Lite (released Dec. 2024)
- AWS Nova Micro (released Dec. 2024)
And to make this benchmarking a real party, we will also include the following OpenAI models (but they are of course not available through AWS Bedrock, and we'll be making these inferences directly through OpenAI):
- OpenAI o1 mini (released Sep. 2024)
- OpenAI o1 (released Dec. 2024)
- OpenAI GPT-4o (released May 2024)
- OpenAI GPT-4o mini (released Jul. 2024)
Prerequisites
You should have an AWS account. If you don't already have one, it's really easy to sign up. You can follow the steps here.
AWS Credentials
You should also set up your local development credentials. There are quite a few ways to achieve this, ranging from complex (and super secure) to straightforward (suitable for testing and development but not necessarily production).
For simplicity, what you want to obtain are the two keys:
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
There are many resources on how to get them, for example, here.
Boto3
You'll also want to install the AWS python SDK, boto3. Boto3 is one of my all-time favorite python libraries. Once you get used to its workflow, the realm of possibility is endless. You can use boto3 to manage all sorts of AWS services, such as compute (EC2), storage (S3), data science (SageMaker), and generative AI (Bedrock). In terms of how much you can do within one single library, boto3 has an excellent ROI to learn. You can install it just like any python library, for example, uv pip install boto3.

Initialize a Client
AWS has more than 200 services. The usual recipe to access an AWS service through boto3 is:
- Initialize a client for the service with your AWS credentials
- With the service client, use the available methods to interact with the service
For example, for making inference calls to Bedrock AI models, the service is called bedrock-runtime, and we can initialize the client like the following:
import os
import boto3
bedrock = boto3.client(
service_name="bedrock-runtime",
aws_access_key_id=os.environ.get("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.environ.get("AWS_SECRET_ACCESS_KEY"),
region_name="us-east-1"
)
Now with the bedrock client, you have access to all the methods listed in the boto3 documentation.
Model Inference
Before May 2024, the standard method to call an AI model in Bedrock is to use the invoke_model() method (documentation). Since Bedrock allows you to access models from different providers, each provider might require different parameters. So invoke_model() takes in a raw request body which you can supply in json format. For example, below is how you can use Bedrock to ask Claude Sonnet 3.5 a question.
import json
import os
import boto3
model_id = "us.anthropic.claude-3-5-sonnet-20241022-v2:0"
bedrock = boto3.client(
service_name="bedrock-runtime",
aws_access_key_id=os.environ.get("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.environ.get("AWS_SECRET_ACCESS_KEY"),
region_name="us-east-1"
)
body = json.dumps({
"max_tokens": 4096,
"messages": [{"role": "user", "content": "Who is the first president of the United States?"}],
"anthropic_version": "bedrock-2023-05-31"
})
response = bedrock.invoke_model(body=body, modelId=model_id)
response_body = json.loads(response.get("body").read())
print(response_body.get("content"))
While this works quite well, having to look up provider-specific parameters for model inference can be tedious when you are interfacing with multiple models. Moreover, you don't know if the parameters you are providing are correct (no type checking) until the inference request fails.
In May 2024, AWS introduced a new method called converse(), which provides a consolidated interface for working with different models. With converse(), making an inference call no longer requires a raw json request.
import os
import boto3
model_id = "us.anthropic.claude-3-5-sonnet-20241022-v2:0"
bedrock = boto3.client(
service_name="bedrock-runtime",
aws_access_key_id=os.environ.get("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.environ.get("AWS_SECRET_ACCESS_KEY"),
region_name="us-east-1"
)
response = bedrock.converse(
modelId=model_id,
messages=[
{
"role": "user",
"content": [
{
"text": "Who is the first president of the United States?"
}
]
}
],
inferenceConfig={
'maxTokens': 4096,
}
)
print(response["output"]["message"]["content"][0]["text"])
Much simpler, right? So here we will use the converse() end point.
Set up Jeopardy! Benchmarking
Last time when we did the Jeopardy benchmarking with DeepSeek R1, we didn't pass in the question category, which made it extra difficult for the models to get the right answers.
This time we will match the actual Jeopardy game better by providing both the question and the category. Other than that, we don't have to change our code too much from the previous benchmarking.
import json
import os
import time
import boto3
import pandas as pd
from tqdm import tqdm
df = pd.read_csv("jeopardy_samples.csv")
# Nova Lite v1
# model_id = "us.amazon.nova-lite-v1:0"
# output_file = "jeopardy_results_nova_lite_v1.csv"
# Nova Micro v1
# model_id = "us.amazon.nova-micro-v1:0"
# output_file = "jeopardy_results_nova_micro_v1.csv"
# Nova Pro v1
model_id = "us.amazon.nova-pro-v1:0"
output_file = "jeopardy_results_nova_pro_v1.csv"
# Iterate through other models.
bedrock = boto3.client(
service_name="bedrock-runtime",
aws_access_key_id=os.environ.get("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.environ.get("AWS_SECRET_ACCESS_KEY"),
region_name="us-east-1"
)
questions = df[" Question"]
categories = df[" Category"]
answers_correct = df[" Answer"]
answers_full = []
answers_short = []
response_times = []
for category, question in tqdm(zip(categories, questions), total=len(categories)):
ti = time.time()
response = bedrock.converse(
modelId=model_id,
messages=[
{
"role": "user",
"content": [
{
"text": (f"""\
You are a Jeopardy game contestant. \
You are extremely knowledgeable about Jeopardy trivia. \
You will be give a Jeopardy category, and a question in the category. \
You should then provide the answer to the question. \
Provide just the answer, no other text. \
You don't have to structure the answer as a question - just provide the answer and nothing else. \
Category: {category}
Question: {question}
""")
}
]
}
],
inferenceConfig={
'maxTokens': 4096,
}
)
tf = time.time()
answer_full = response["output"]["message"]["content"][0]["text"]
answers_full.append(answer_full)
answer_short = answer_full.split("\n")[-1]
answers_short.append(answer_short)
response_times.append(tf - ti)
# Adjust sleep time based on model quota.
# There is a "request per minute" quota for each model.
time.sleep(1)
# Create a new df to save the results.
df = pd.DataFrame()
df["Question"] = questions
df["Category"] = categories
df["Answer_full"] = answers_full
df["Answer_short"] = answers_short
df["Answer_correct"] = answers_correct
df["Time"] = response_times
df.to_csv(output_file, index=False)
Now we can iterate through all the models available in AWS Bedrock and get results!
Benchmark Results
Here are the benchmark results. Maybe it's helpful for you to pick an optimal model next time you have to answer a bunch of trivia questions.
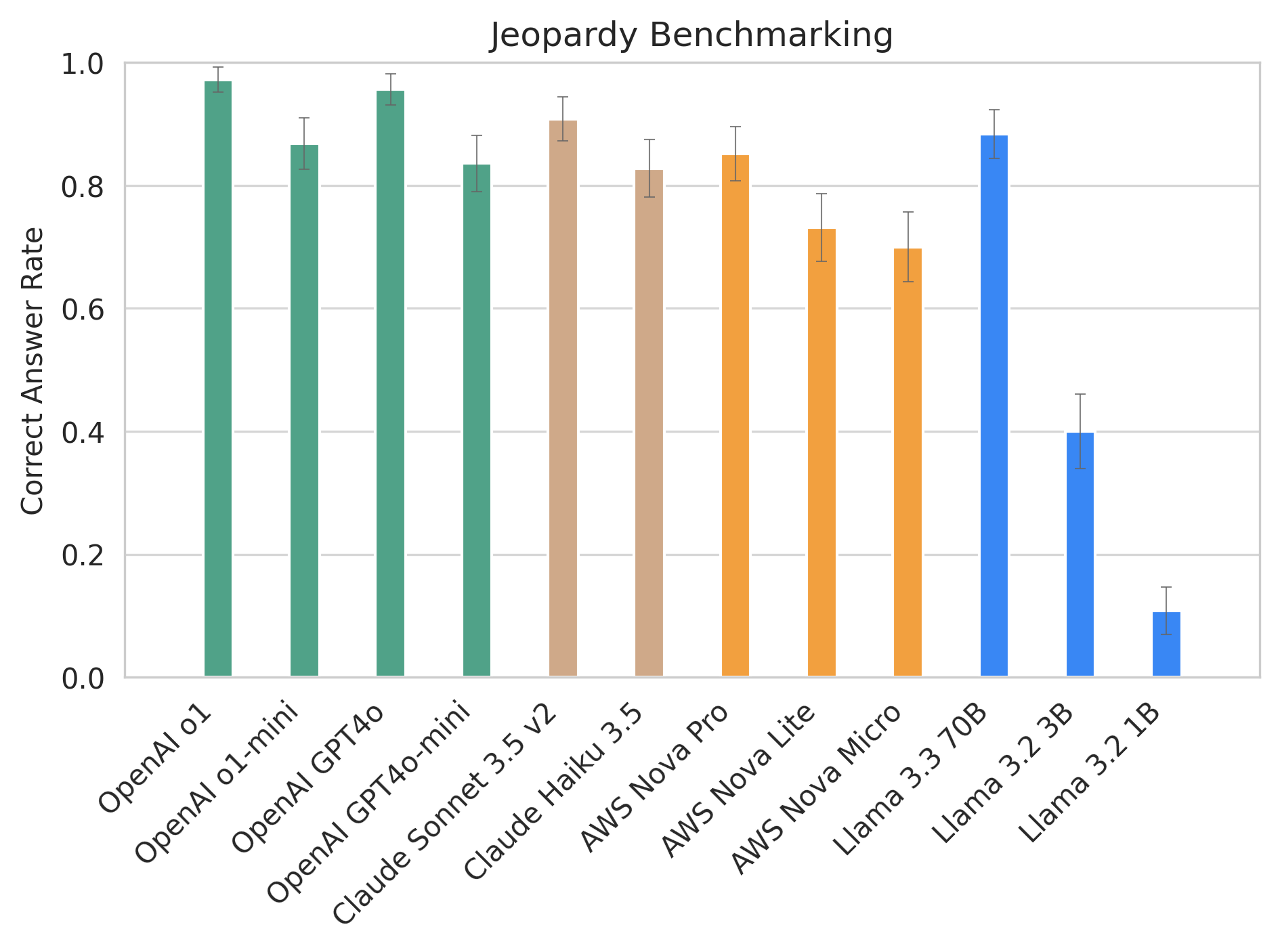
But being correct is not the only factor to consider when choosing a model. When building an AI-enabled product, being able to return results quickly also matters. So we added speed into consideration. We can confirm that, generally, larger models with more weight take longer to respond. Reasoning models like OpenAI o1 also take longer (as it has to "think").
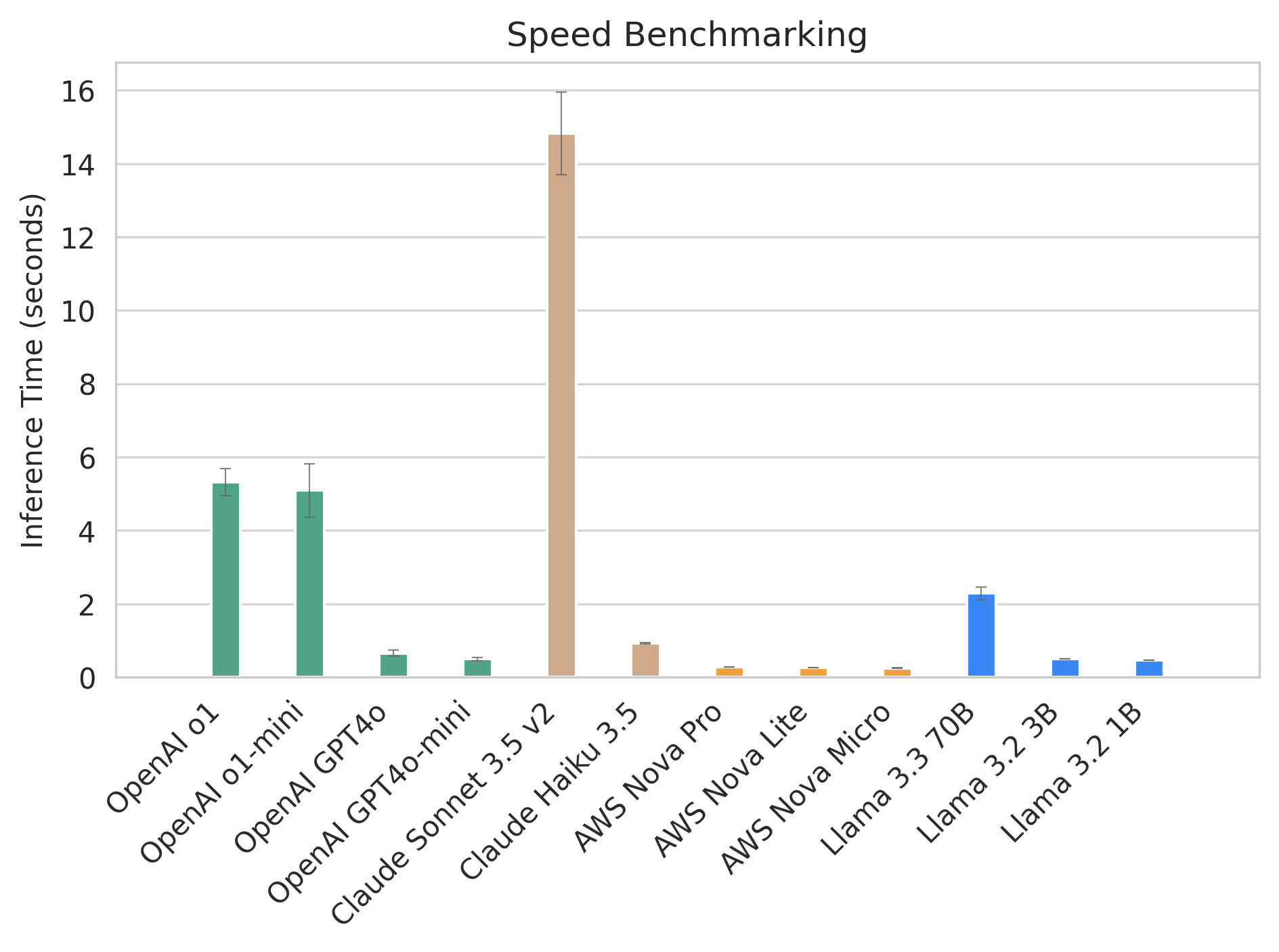
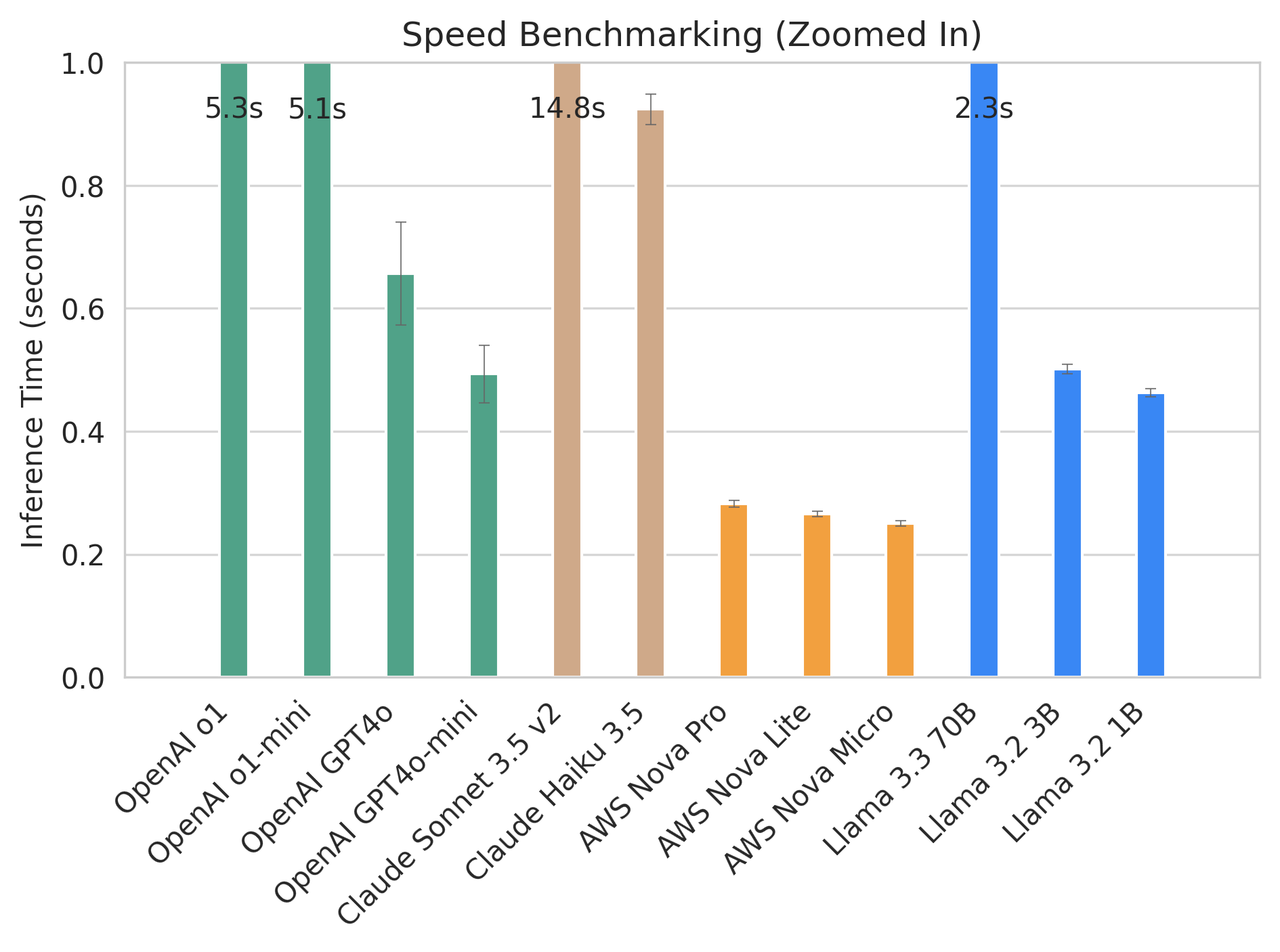
Considering both speed and quality, the AWS Nova Pro looks pretty appealing!
Wrapping Up
AWS Bedrock is a powerful AI platform. Through Bedrock, you can leverage different foundational models easily. New and more powerful models are constantly being released. AWS Bedrock makes it possible to stay up-to-date, since you can quickly switch and test new models. You can also extend on the model catalog by fine-tuning with more examples, or using a custom model that is open weight. For example, you can import DeepSeek R1 as a custom model and make inference calls through Bedrock. Within 10 days of DeepSeek R1 release, AWS also made them available on Bedrock.
Whether you are a data scientist exploring LLM models, or an AI engineer building the next hit app, AWS Bedrock should be a part of your tool box!



