


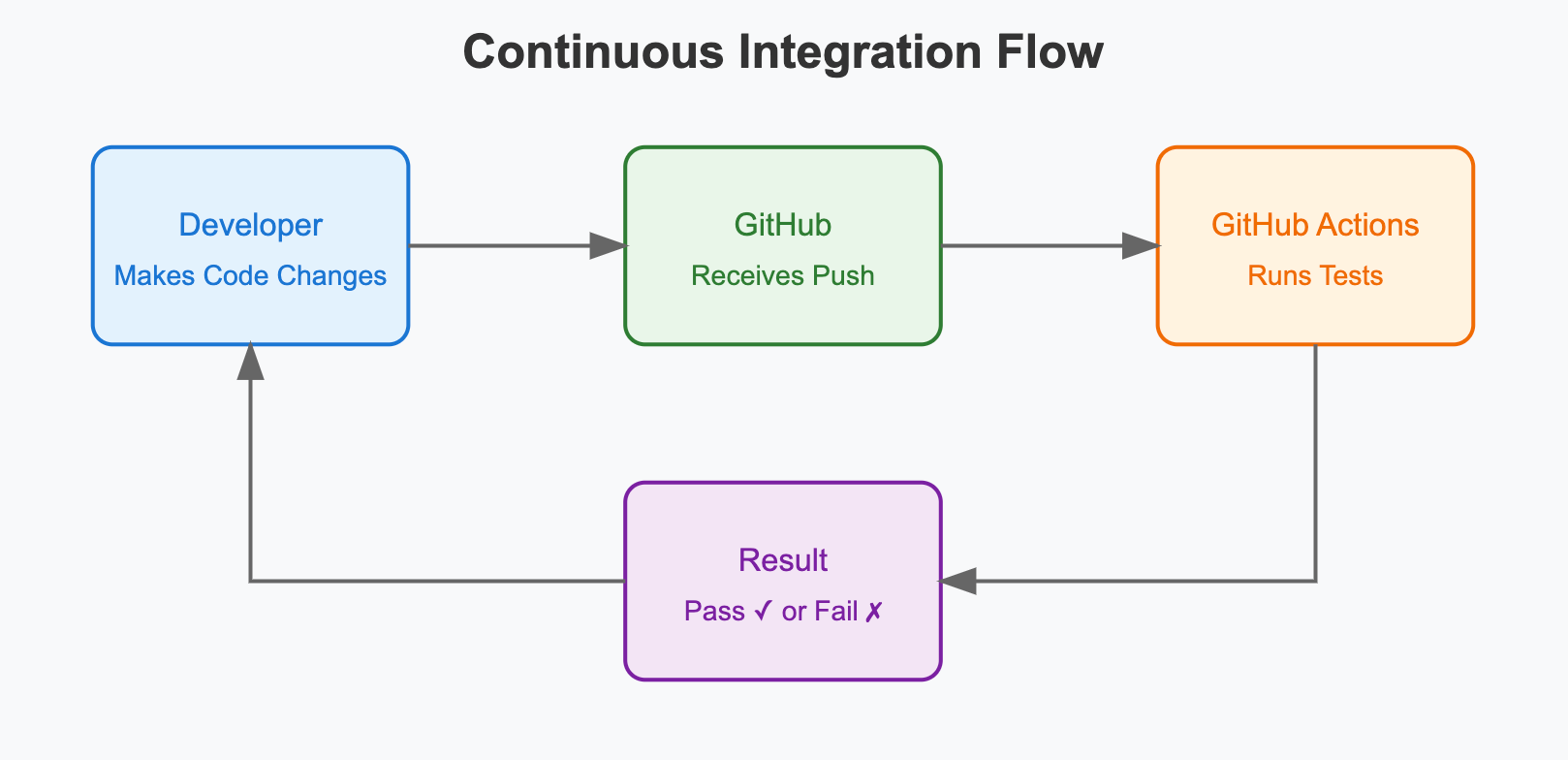
As data scientists, we write a lot of code that others depend on. Maybe it's a data preprocessing pipeline that feeds into dashboards, or a feature engineering module that powers your ML models in production. Your teammates and stakeholders rely on your code to work consistently.
But we've all been there - you make a small change to improve something, and suddenly:
- Your colleague's notebook breaks because a function output changed
- The weekly reports show weird numbers because a data transformation changed
- The model training pipeline fails because a feature is missing
This is where Continuous Integration (CI) comes in. Without CI, we're essentially building a house of cards - one wrong move and everything could collapse. With CI, we can methodically build something magnificent, brick by brick, with each addition tested and verified. Like a master architect ensuring every component is sound before adding the next level, CI helps us construct robust, reliable code that stands the test of time.


Building things without continuous integration (left) versus with continuous integration (right). Image credits: freepik (left) and Lil Mayer / Unsplash (right)
Main Components of CI
The power of CI comes from three main ingredients:
- Automated Tests: Your first line of defense. These are test codes that verify expected behaviors are being preserved with every change:
- Unit tests check individual functions work correctly
- Integration tests ensure different parts of your code work together
- Regression tests catch if new changes break existing functionality
- Code Quality Checks: These keep your codebase clean and maintainable.
- Linting catches potential errors and enforces coding standards
- Style checks ensure consistent formatting across the team
- Type checking (in languages that support it) catches type-related bugs early, instead of letting the bugs bubble up in production
- Automated Triggers: The "continuous" part of CI.
- Tests run automatically when code is pushed
- Results are immediately reported to developers
- Failed checks block code from being merged
- Success gives confidence to deploy changes
Prerequisites
For today's one day tour, we will set up a simple continuous integration workflow that checks against a python code base, using GitHub actions. That means you should have:
- A GitHub account, and a repository where you can make changes and push code.
- Some python code with corresponding tests. If you don't have them, don't worry. Check out our Python Unit Testing One Day Tour to set them up.
Setting Up Tests
Here is the folder structure we will use. In our repository, we have a folder called python-unit-testing – this is where we are storing the code we wrote for the Python Unit Testing One Day Tour.
.
└── python-unit-testing/
├── param_initializer.py
├── simple_neural_net.py
└── test_simple_neural_net.pyAnd I'm also including the content of these files below so you can easily replicate.
"""param_initializer.py"""
def get_params():
pass"""simple_neural_net.py"""
from param_initializer import get_params
class SimpleNeuralNet:
def __init__(self):
params = get_params()
self.weight = params["weight"]
self.bias = params["bias"]
def relu(self, x):
return max(0, x)
def forward_propagation(self, x):
return self.relu(x * self.weight + self.bias)"""test_simple_neural_net.py"""
import unittest
from unittest.mock import patch
import simple_neural_net
class TestSimpleNeuralNet(unittest.TestCase):
@patch('simple_neural_net.get_params')
def setUp(self, mock_get_params):
mock_get_params.return_value = {"weight": 1, "bias": 2}
self.snn = simple_neural_net.SimpleNeuralNet()
mock_get_params.assert_called_once()
def test_store_params(self):
self.assertEqual(self.snn.weight, 1)
self.assertEqual(self.snn.bias, 2)
def test_update_params(self):
self.snn.weight = 0.1
self.snn.bias = 0.2
self.assertEqual(self.snn.weight, 0.1)
self.assertEqual(self.snn.bias, 0.2)
def test_relu(self):
y = self.snn.relu(x=3)
self.assertEqual(y, 3)
y = self.snn.relu(x=-3)
self.assertEqual(y, 0)
def test_forward_propagation(self):
y = self.snn.forward_propagation(x=3)
# y = 1 * x + 2 = 3 + 2 = 5 which is still 5 after ReLU
self.assertEqual(y, 5)
y = self.snn.forward_propagation(x=-10)
# y = 1 * x + 2 = -8 + 2 = -6 which is 0 after ReLU
self.assertEqual(y, 0)
if __name__ == '__main__':
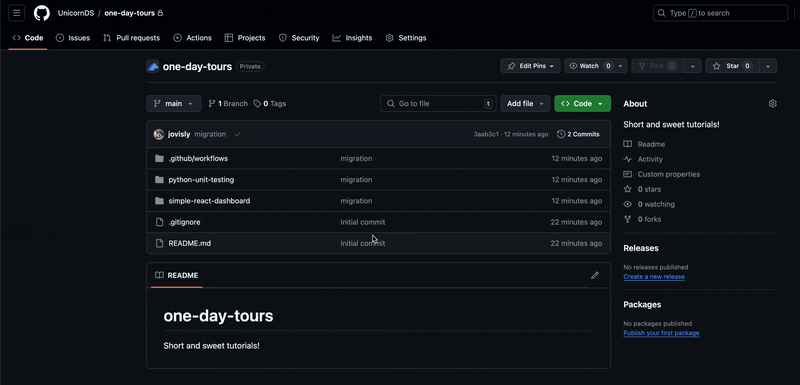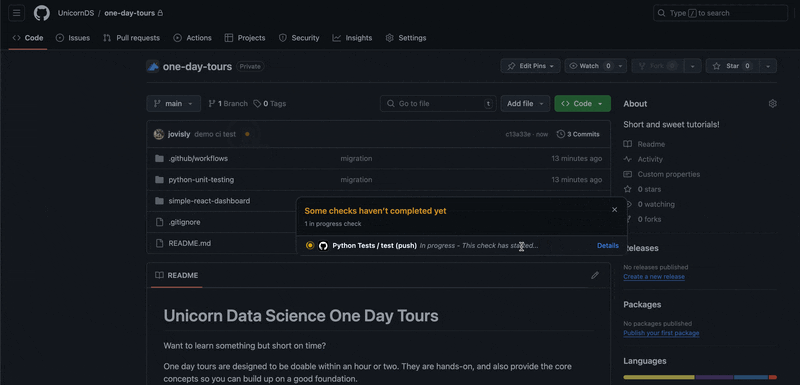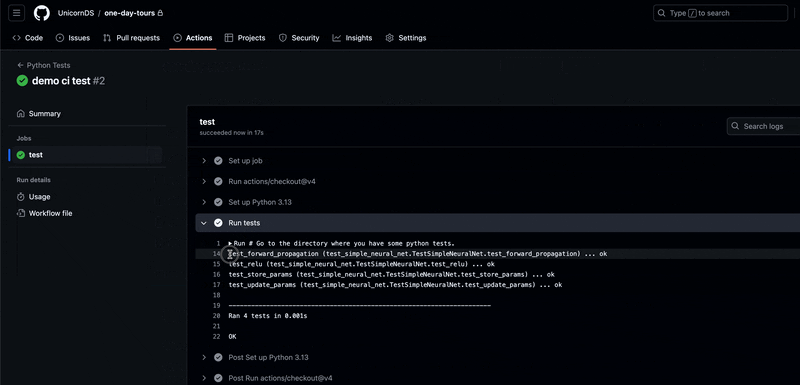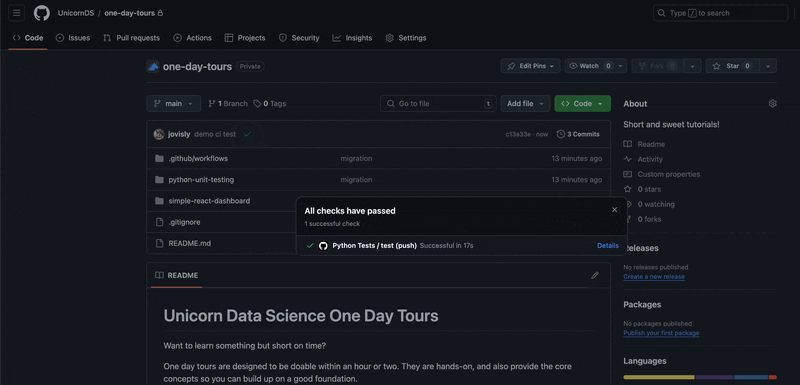
unittest.main()Now that you have all the files set up, if you run the test with python test_simple_neural_net.py in the python-unit-testing folder, you should see that four tests have passed.
/UnicornDS/one-day-tours/python-unit-testing > python test_simple_neural_net.py
....
----------------------------------------------------------------------
Ran 4 tests in 0.001s
OKSetting Up GitHub Actions
Now we will set up a very simple GitHub action that does the following:
- Whenever new code is pushed to the repository to the
mainbranch, automatically run the python tests. - We also typically perform this automated checks when a pull request is opened.
- The automated checks will tell us if the tests have all passed.
Defining GitHub actions is done via yml configuration files. You place these files in the designated path .github/workflows and they are automatically recognized by GitHub. We will create a simple python-test.yml file to define the python test.
This means the updated folder structure will look like:
.
├── .github
│ └── workflows
│ └── python-tests.yml
└── python-unit-testing
├── param_initializer.py
├── simple_neural_net.py
└── test_simple_neural_net.pyThe content of our python-test.yml is shown below, with comments explaining what each line is doing:
# Name of this GitHub Actions workflow - this will appear in the Actions tab of your repository
name: Python Tests
# Defines when this workflow will run
on:
# Trigger workflow on any push to the main branch
push:
branches: [main]
# Trigger workflow on any pull request targeting the main branch
pull_request:
branches: [main]
# A workflow consists of one or more jobs
jobs:
# Define a job named "test"
test:
# Specify the type of machine to run the job on
# ubuntu-latest is a common choice as it's free for public repositories
runs-on: ubuntu-latest
# List of steps to execute in this job
steps:
# Check out your repository code to the runner
# This is required so the runner can access your code
# @v4 specifies the version of the action to use
- uses: actions/checkout@v4
# Set up Python environment
# This step installs Python on the runner
- name: Set up Python 3.13
uses: actions/setup-python@v5
with:
# Specify which Python version to use
# Using quotes around version number is recommended to avoid YAML parsing issues
python-version: "3.13"
# Run your Python tests
- name: Run tests
# The pipe symbol | allows for multiple lines of shell commands
run: |
# Navigate to the directory containing your tests
cd python-unit-testing
# Run unittest with verbose (-v) output
# The -m flag runs unittest as a module
python -m unittest -v
Watch the Actions Happen
As soon as you add the python-test.yml file to your repository, the python tests will be automatically triggered with every push to the main branch (as well as in Pull Requests).
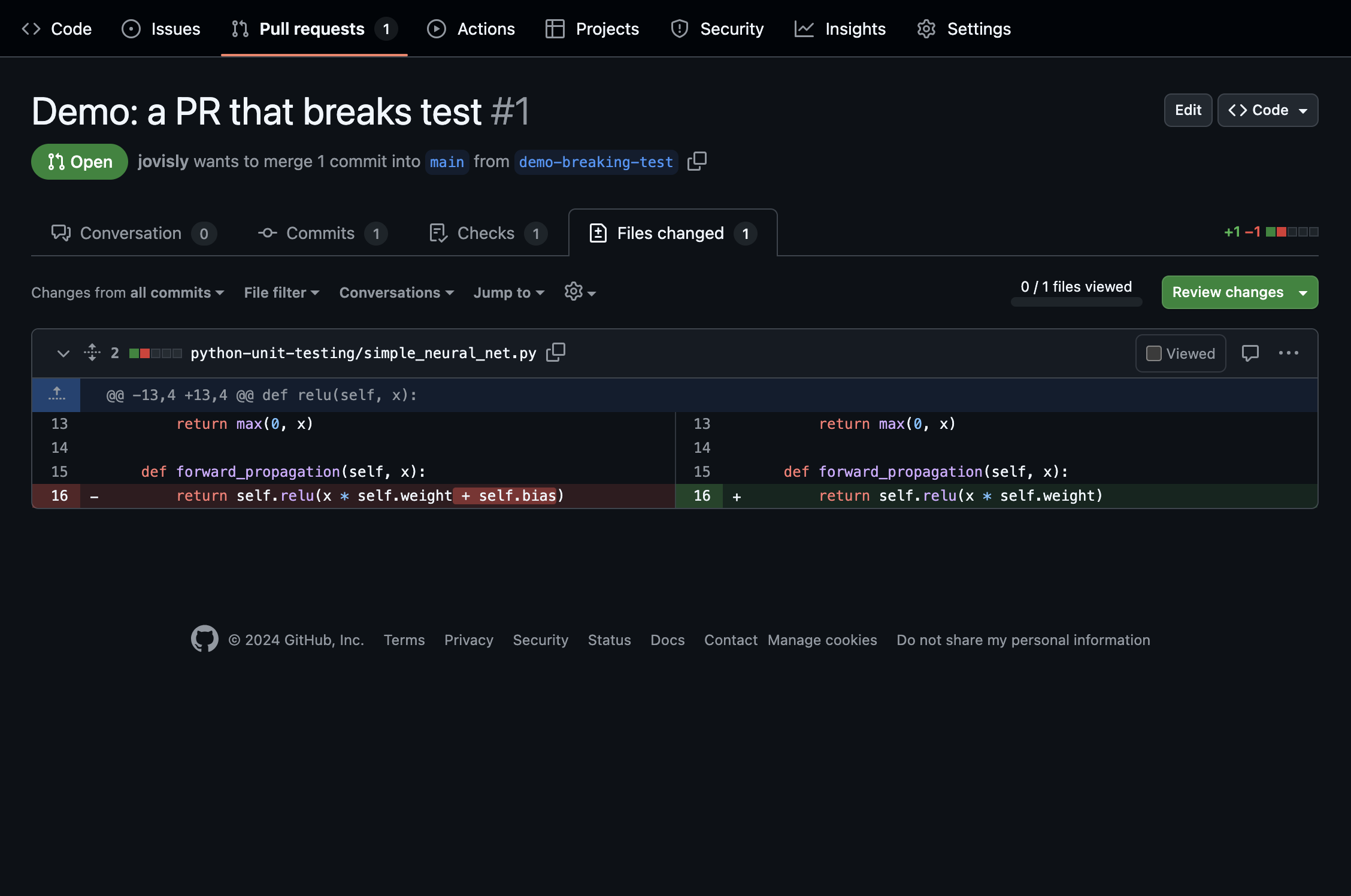
What happens if a test is broken? Let's make an edit to one of the python files and intentionally break the tests. Then let's open a PR. Here is the line we changed: we "accidentally" dropped the bias term in the forward propagation calculation of the neural net!
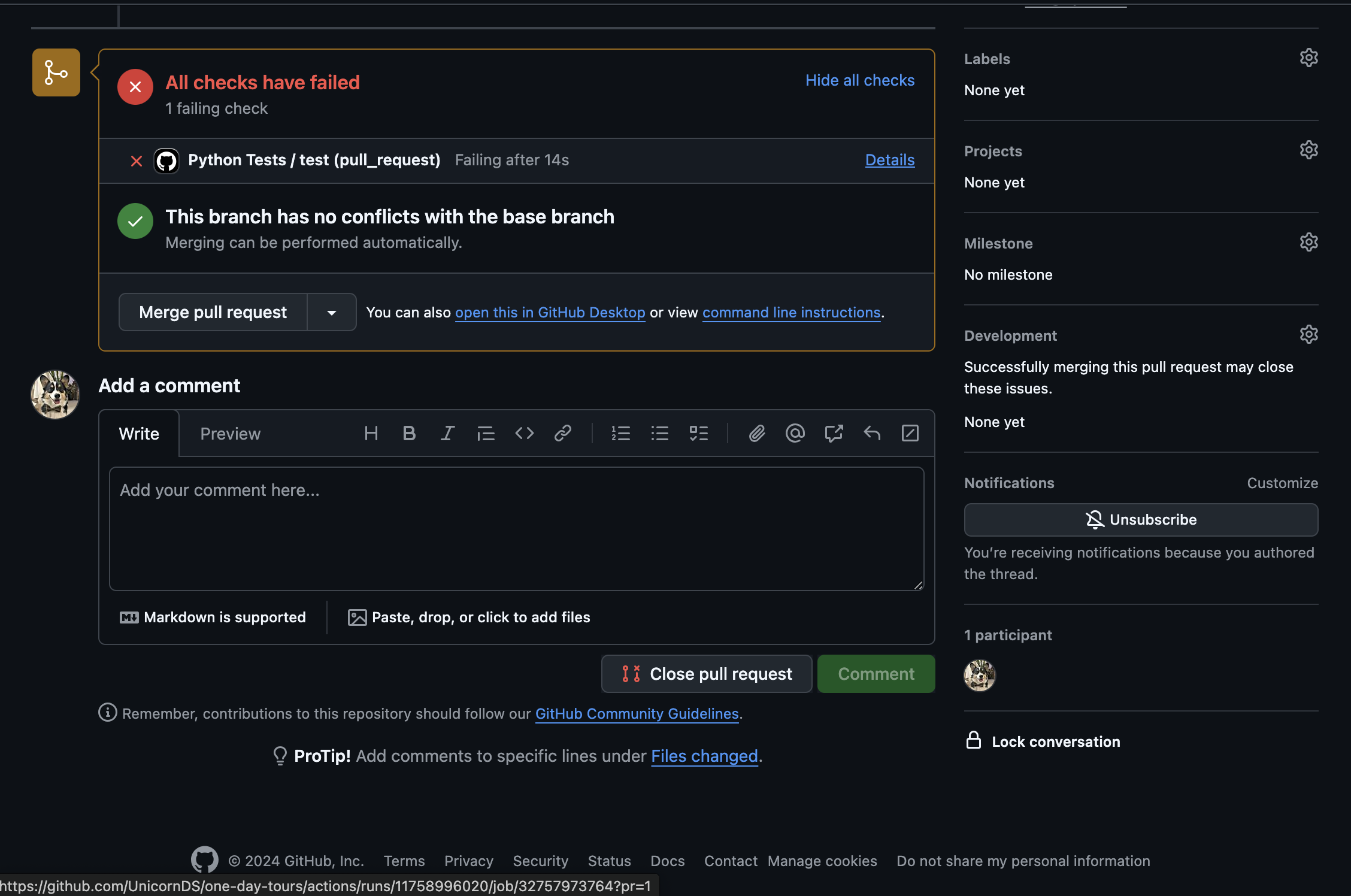
Having such code checked into the codebase would be bad. But thanks to the automated checks by GitHub action, we can see a big red alert for the PR:
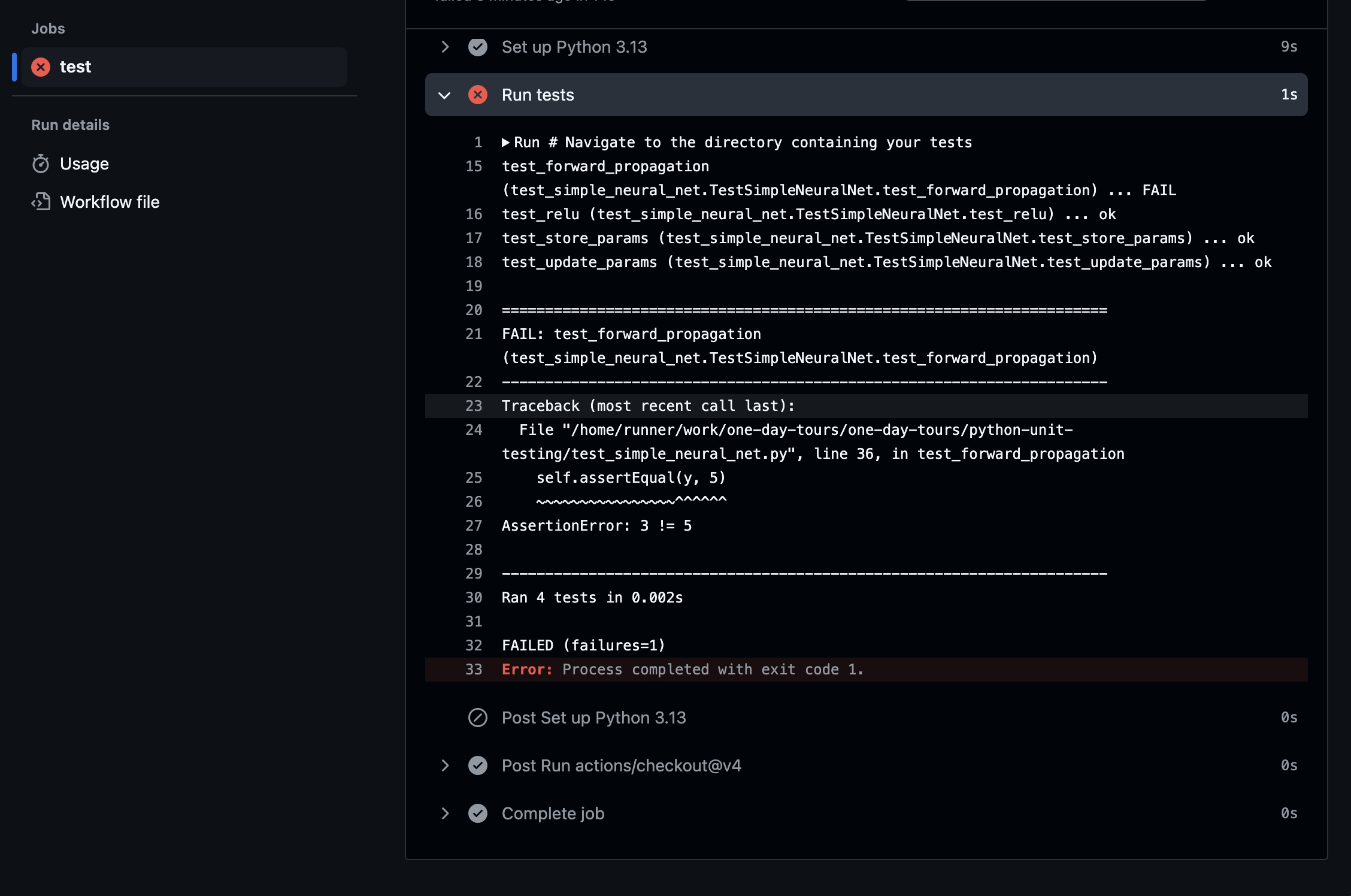
Clicking on "Details" provides the exact test that failed and why:
With checks like these in place, you can build up your project one commit at a time, without worrying about breaking functionalities unintentionally. Of course, this means you need to put in the effort to define what the intended behavior of your code is. That means diligently writing tests that precisely define how your code should behave under different circumstances. While this might sound laborious, over the long run, you will be able to build robust and maintainable projects!



