


In academia, the axiom "publish or perish" reflects the need for researchers to disseminate their findings, in order to make impact and advance their careers.
Similarly, in data science, analyzing data alone is not enough. You are already aware of how important communication is in data science. We need to produce engaging data visuals. We need to be able to tell insightful and factful data stories to stakeholders. It's common to spend days analyzing data, and then equally long to prepare a presentation. If it's well-received, you might get to present it multiple times to different teams. I like to call this "nerd hours turning into nerd tours": the solitary hours of data analysis lead to meaningful results worth sharing, which then lead to rapid succession of presentations to multiple audiences. It is very rewarding to see your analysis generating excitement and discussion.
But excitement is fleeting. No matter how compelling your analysis or how polished your presentation, new information is always coming in. Today's impactful insights become tomorrow's dusty slide decks, and the cycle repeats.
The Case for Productization in Data Science
I have experienced this cycle many times. And many data scientists have similarly felt demotivated at some point in their careers by the lack of sustained impact from their hard work.
How can we break this cycle? What if instead of our analyses being single-use artifacts, they could continue delivering value? The key lies in how we think about our work: not as isolated, one-off analyses, but as opportunities to build lasting solutions.
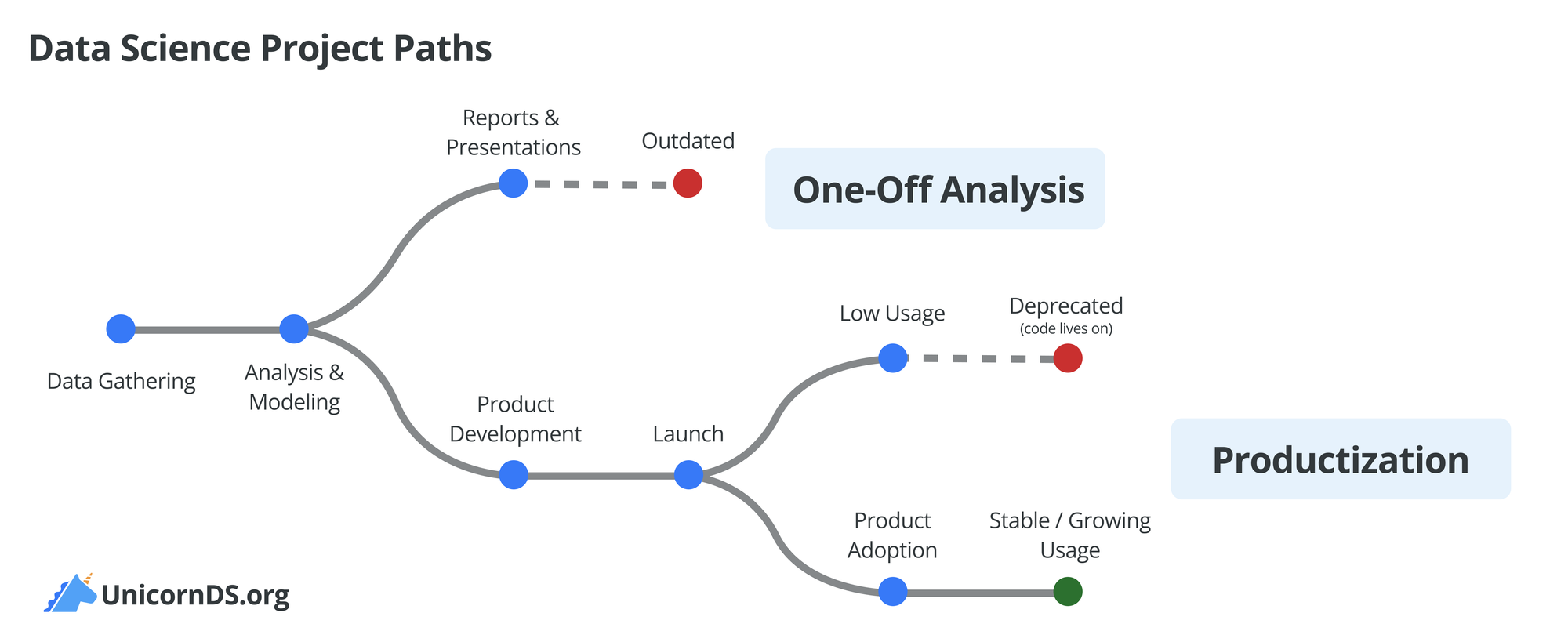
Examples
Let's look at three common ways to productize data science work.
1 - From One-off Analysis to Dashboard, Alert and Monitoring
Instead of: Pull data and conduct analysis; create reports and presentation slides
How about: Build a dashboard that monitors metrics 24/7 and alerts stakeholders when there are notable trends
2 - From ML Models to Inference Services
Instead of: A trained model that lives in a Jupyter notebook, accessible only to the data scientist
How about: API endpoints that any internal system can query for real-time predictions
3 - From Ad-hoc Data Wrangling Scripts to Automated Data Pipeline
Instead of: Manual data cleaning scripts that require constant tweaking and troubleshooting
How about: Automated pipeline with quality checks, error handling, and logging
Challenges
The path from analysis to product is filled with challenges. The biggest hurdle? A skills gap. Data scientists are trained to analyze data and build models, but productization requires software engineering skills: API design, testing, monitoring, and deployment. This transition from notebook to production code is often unfamiliar territory.
But this hurdle is actually more approachable than it might seem. Many data scientists are eager to expand their skillset when it means increasing their impact. Organizations can accelerate this transition through training and mentorship, or by fostering partnerships between data scientists and software engineers. Modern tools and platforms are also making it increasingly easier to build production-ready data products. For example, tools like Streamlit and Gradio now allow data scientists to build web applications with minimal engineering overhead. The gap between analysis and product is narrowing - we just need to be intentional and strategic about bridging it.
Closing Thoughts
Our impact as data scientists and data teams will depend on our ability to create lasting solutions. While analytics and modeling will remain foundational to data science, productization allows us to amplify and sustain their value over time.
Let's productize.



