


It is overwhelming how much there is to learn when it comes to data science mastery. Data analytics, data visualization, data story telling, data engineering, machine learning, statistics, probability theory, natural language processing, AI; the list seems to be growing every day!
One of the most common debate a data scientist encounters early on in their learning journey is which language, R or Python, to get deeper into. Both are extremely powerful. Both are filled with resources to get stuff done. Both come with amazing community support.
We are not going to add to this debate. Instead, I'd like to propose an alternative: SQL. I'm not saying SQL can do everything R and Python can; that'd be silly. But we are assuming you are already working as a Data Scientist, so you should currently have enough knowledge of R, Python, and likely even SQL, for your day-to-day role. And the question is, which language to invest and get really good at? In that case, oftentimes SQL can provide the biggest return on your time investment.
High ROI Data Engineering
The primary reason that SQL is a powerful tool to learn for a Data Scientist is that it provides a key into the realm of data engineering.
Data scientists can't do science without data. So having the skills to bring in data, and manipulate it at a large scale unlocks a whole new world of possibilities.
And as data scientists, we are already familiar with SQL as the language to query data. We can combine different tables with joins, and create simple aggregate statistics with group by. Usually we use SQL to pull the data we need from a database, then use perhaps R or Python to perform further analysis or processing.
Distributed SQL Engines
What's happening behind the scene when we execute these "join" and "group by" operations is that, depending on the SQL engine, sophisticated, parallelized workloads are automatically carried out to scale up with your data size.
Dremel: SQL Analysis of Web-Scale Datasets
In 2010, Google Research published a paper describing Dremel, a distributed SQL engine. Dremel is capable of analyzing trillion rows of data in seconds by using sophisticated map-reduce algorithms under the hood. Today, you can use Dremel in the cloud with Google Cloud's BigQuery. Without knowing how to do distributed computing, you can already unleash the power of Dremel and extract insights from arbitrarily large datasets.
Presto: SQL on Everything
The Dremel paper described it as an analytical engine. But in 2019, Meta Research published a paper titled "Presto: SQL on Everything". This is another eye-opening paper, and elevates distributed SQL engine from the analytics use case to also large-scale ETL (extract, transform, load) and data warehouse workflows.
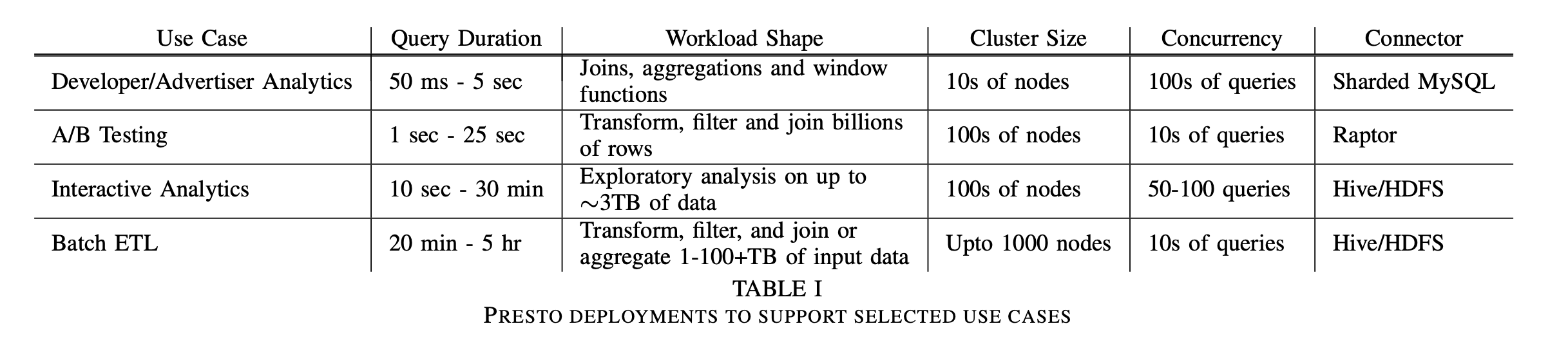
This means that with one language (SQL), you can do a wide variety of things. Business analysts can use SQL to query data from multiple sources. Data Scientists can use SQL to perform complex data transformations. Data Engineers can use SQL to build scalable data pipelines. And because it's the same language, there is the "learn once, write anywhere" advantage (this is a slogan typically used by React, yet another Meta-released software). If you master the ins and outs of SQL, opportunities open up for you.
Distributed SQL Engines are Everywhere
You don't have to work at Meta or Google to benefit from distributed SQL engines. Besides BigQuery, which you can use through Google Cloud, there is also AWS Athena which was built on top of Presto. Modern data processing platforms typically support SQL. For example, Apache Spark was originally released for Scala. Later on, support for other languages such as Java and Python (PySpark) were added. Now, you can also use SQL with Spark (Spark SQL).
Heard from the Field
My enthusiasm for SQL grew out of witnessing its practicality in the real world. In multiple instances, SQL-based data pipelines built by a data science team were not only performant for production workflows, but also scalable to terabytes of data, and maintainable over time.
In one case, the engineering team we were collaborating with finally had some bandwidth after launching our product. So we were going to rewrite the SQL data pipeline in Java, thinking it'd give us a performance gain. But after examining the code, and doing the cost-benefit evaluation, the engineering team came to the conclusion that the SQL pipeline was as good as it was going to get, regardless of the language.
In another instance, for a different project, we worked with an engineering team who was in the process of migrating their primary language to Go. Our SQL-based ETL pipeline was also included in the migration effort. However, after a few months, coming back to the codebase, we realized that the SQL portion was preserved nearly intact. What was changed was that the original Python SQL engine client was replaced with a Go client. This meant the data scientists who originally worked on the data pipeline could continue to contribute meaningfully to the project.
Tips for Leveraging Large Scale SQL-based Data Engineering
Even though you can leverage powerful SQL engines without understanding the intricacies of distributed computing, there are a lot of tips to keep in mind if you want your data pipeline to scale well.
And every SQL engine has its own quirks and nuances. So it's important to know which engine you are using, and how to optimize it. For example, if you are using Presto through AWS Athena, the Athena performance tips is a required reading. BigQuery similarly has its own set of best practices.
While every SQL engine is slightly different, broadly speaking, there are some common performance tips worth mentioning:
- Organize your data with practical partitioning: Partitioning is a technique to split your data into smaller chunks, and organize them into, e.g., different folders, paths, or tables. If you define a partitioning scheme based on how the data is often queried, you can reduce the amount of data that needs to be scanned, and thus improve the performance of your queries.
- Don't like "LIKE" too much: The LIKE operator is a powerful tool to filter data, but it can also be very slow depending on the length of the string field, and your query engine. Use it mindfully.
- JOIN keys should not be too skewed: When you JOIN two tables, you are essentially combining the rows of both tables, and this operation is often parallelized into multiple tasks. If the JOIN key is skewed, the one task can have a disproportionate amount of work to do, introducing bottlenecks. To avoid this, make sure your JOIN keys are nicely distributed. In addition, JOIN direction (LEFT JOIN vs RIGHT JOIN) matters. Depending on the query engine, you might need to be mindful how big each table is on either side of the JOIN.
- Intermediary or temporary tables: As your SQL-fu grows, so will the complexity and length of your queries. Typically, distributed SQL engines are capable of breaking down a big query into multiple steps automatically. But if your query is too complex, you can help the query engine by creating intermediary tables. Some query engines even support temporary tables, which only exist for the duration of the query. Leverage these features to make your queries more efficient. You will also get an extra benefit of more readable code, as your query logic would be clearly grouped into multiple steps.
Not without Caveats: Testing Frameworks
Despite its power, a SQL-based data pipeline is not without its pitfalls. For example, SQL codes can be hard to read, and it's easy to make logical mistakes. A little mistake in the data pipeline logic will propagate to all the downstream systems. And if it's powering decision making, such as business reporting, it can lead to wrong company strategies.
Many years ago, we had a business reporting pipeline that's been running for as long as I could remember. Each day, the pipeline randomly sampled and analyzed 100 transactions within the last 24 hours, so we could be alerted of any purchasing trend changes. At some point, the underlying data source was getting an update, which brought us to look at this SQL query a bit closer. We found out that what we thought was random sampling was actually done with:
LIMIT 100Imagine our shock!
To mitigate unintentional errors like this, it's important to have a testing framework in place. In terms of testing framework maturity, SQL is lagging behind other major languages. However, as popularity of SQL-based data pipelines grows, more and more testing methodologies are being developed. You should be aware of what testing options are available for your SQL engine. And always write your SQL codes with readability and maintainability in mind.
In summary, mastering SQL offers immense benefits for data scientists. It opens doors to powerful data engineering and scalable solutions. Despite some challenges, its growing ecosystem ensures SQL remains invaluable in your data science toolkit.



