On Jan. 20, DeepSeek released the open-weight R1 model that is remarkably performant, and we tried it out immediately. Our previous benchmarking on R1 model (the 32B and 70B variants) utilized Ollama, running the inferences locally.
Within less than 2 weeks, Amazon announced the availability of the DeepSeek R1 model on AWS. Being also a big fan of AWS Bedrock, I couldn't wait to test it. But obtaining all the required service quota took some time, so finally today, we've got all the pieces lined up, and we will deploy DeepSeek models on Bedrock to test its performance!
The Various Options of Running DeepSeek on AWS
Just a few days after DeepSeek R1 release, AWS team published instruction on how to run DeepSeek models on AWS with the Bedrock custom model import. Since DeepSeek models are open weight, they are very suitable for Bedrock's custom model feature. Simply upload the model weights into S3, and set up the custom model in Bedrock.
In practice though, given the DeepSeek model weight, both pulling the model to my local machine and uploading the model to S3 can take a long time. I can alternatively set up an EC2 machine to pull the model then upload, but that's a lot of steps.
So my ideal approach is to use Bedrock marketplace, which now offers DeepSeek models. Then a model endpoint can be deployed, which provides a model id that can be used the same way as other Bedrock models we have benchmarked previously. Sounds very doable!

However, such deployment requires having some quota for the SageMaker instance type. By default, the quota available for a new AWS account is 0. A quota increase request to AWS support is needed to gain access.
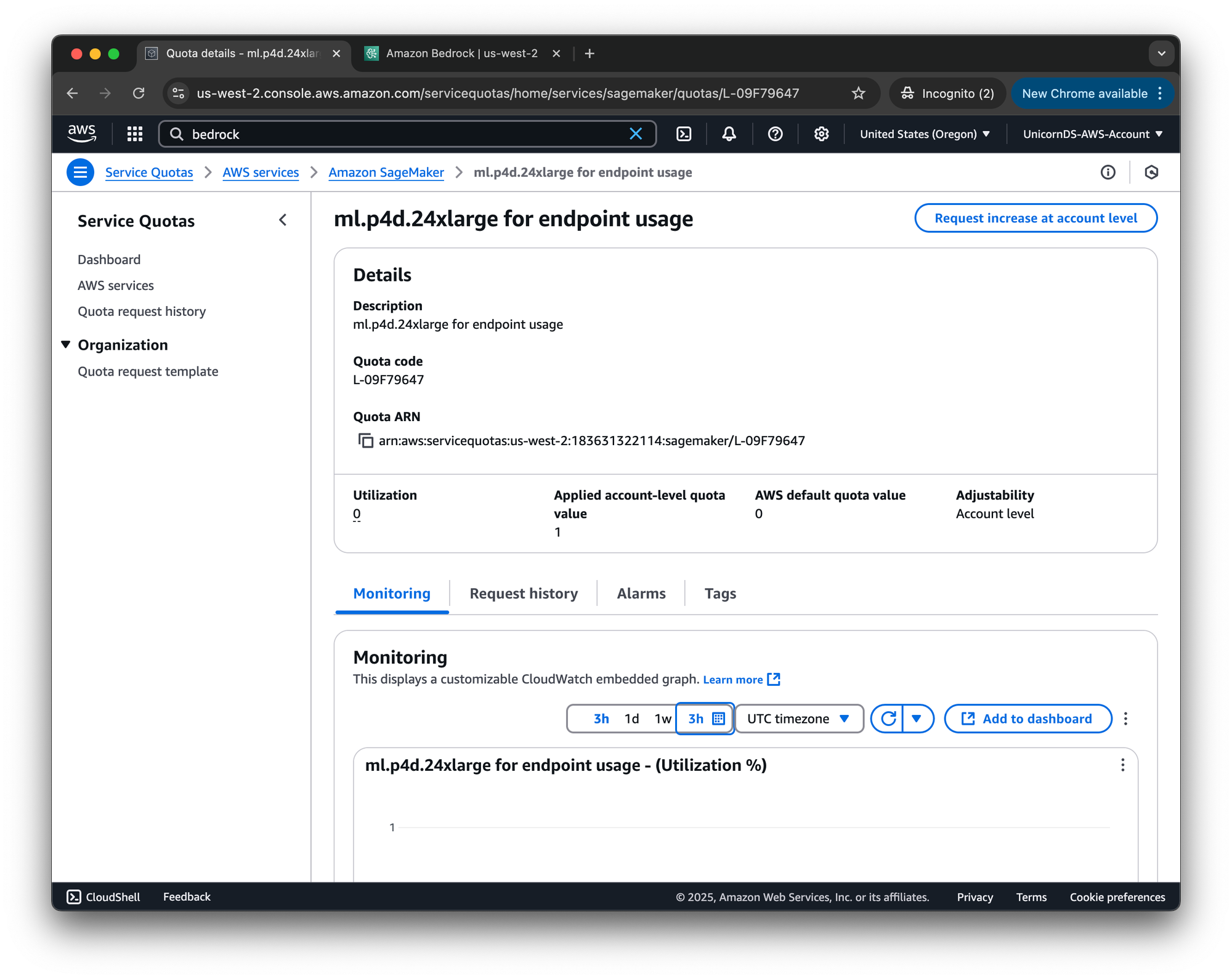
ml.p4d.24xlarge endpoint usage (the recommended instance). This can take some time, especially if you have a new AWS account. But it's a very powerful resource!Initially I requested quota increase for the ml.p5e.48xlarge instance, as described in the original instruction. After a couple of weeks, my request was approved, but the supported instances for marketplace deployments have since been updated. So I requested ml.p4d.24xlarge. The second request was approve quickly, within days.
Bedrock Marketplace Deployment
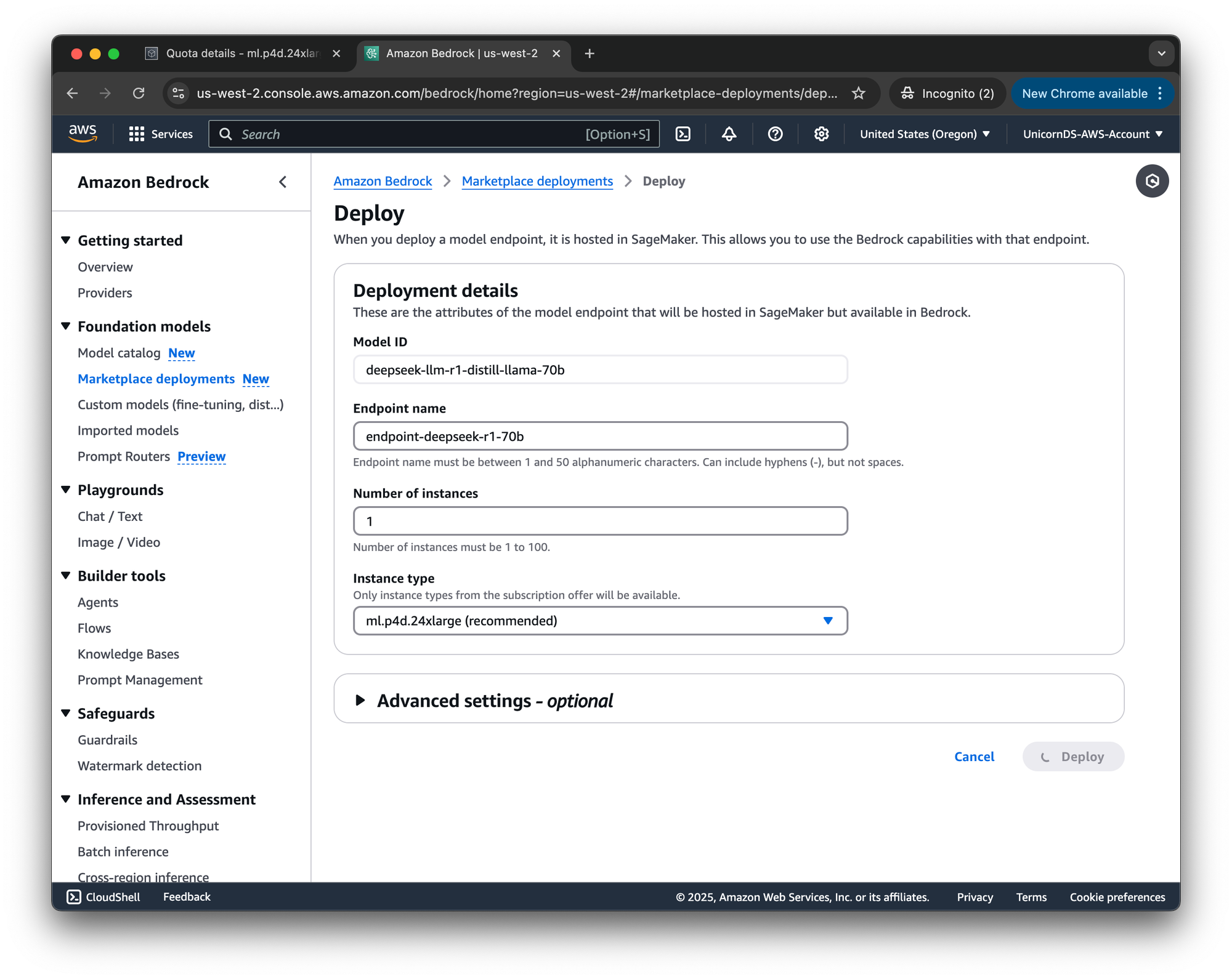
Once equipped with ml.p4d.24xlarge quota, we can start a deployment. With the 70B model, deployment only took a few minutes. Afterwards, the model is available.
import json
import os
import time
import boto3
import pandas as pd
from tqdm import tqdm
df = pd.read_csv("jeopardy_samples.csv")
# 70b
# model_id = "arn:aws:sagemaker:us-west-2:123456789:endpoint/endpoint-deepseek-r1-70b"
# output_file = "jeopardy_results_deepseek_70b.csv"
# 32b
model_id = "arn:aws:sagemaker:us-west-2:123456789:endpoint/endpoint-deepseek-r1-32b"
output_file = "jeopardy_results_deepseek_32b.csv"
bedrock = boto3.client(
service_name="bedrock-runtime",
aws_access_key_id=os.environ.get("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.environ.get("AWS_SECRET_ACCESS_KEY"),
region_name="us-west-2"
)
questions = df[" Question"]
categories = df[" Category"]
answers_correct = df[" Answer"]
answers_full = []
answers_short = []
response_times = []
for category, question in tqdm(zip(categories, questions), total=len(categories)):
ti = time.time()
response = bedrock.converse(
modelId=model_id,
messages=[
{
"role": "user",
"content": [
{
"text": (f"""\
You are a Jeopardy game contestant. \
You are extremely knowledgeable about Jeopardy trivia. \
You will be give a Jeopardy category, and a question in the category. \
You should then provide the answer to the question. \
Provide just the answer, no other text. \
You don't have to structure the answer as a question - just provide the answer and nothing else. \
Category: {category}
Question: {question}
""")
}
]
}
],
inferenceConfig={
'maxTokens': 4096,
}
)
tf = time.time()
answer_full = response["output"]["message"]["content"][0]["text"]
answers_full.append(answer_full)
answer_short = answer_full.split("\n")[-1]
answers_short.append(answer_short)
response_times.append(tf - ti)
time.sleep(1)
# Create a new df to save the results.
df = pd.DataFrame()
df["Question"] = questions
df["Category"] = categories
df["Answer_full"] = answers_full
df["Answer_short"] = answers_short
df["Answer_correct"] = answers_correct
df["Time"] = response_times
df.to_csv(output_file, index=False)
Benchmark Results
We tested out the DeepSeek-R1-Distill-Qwen-32B model, which was measured to outperform OpenAI-o1-mini. We also tested the 70B variant, which is bigger and should be even more performant.
caffeinate -i python main.py to prevent computer from falling asleep while running benchmarking that can take awhile. 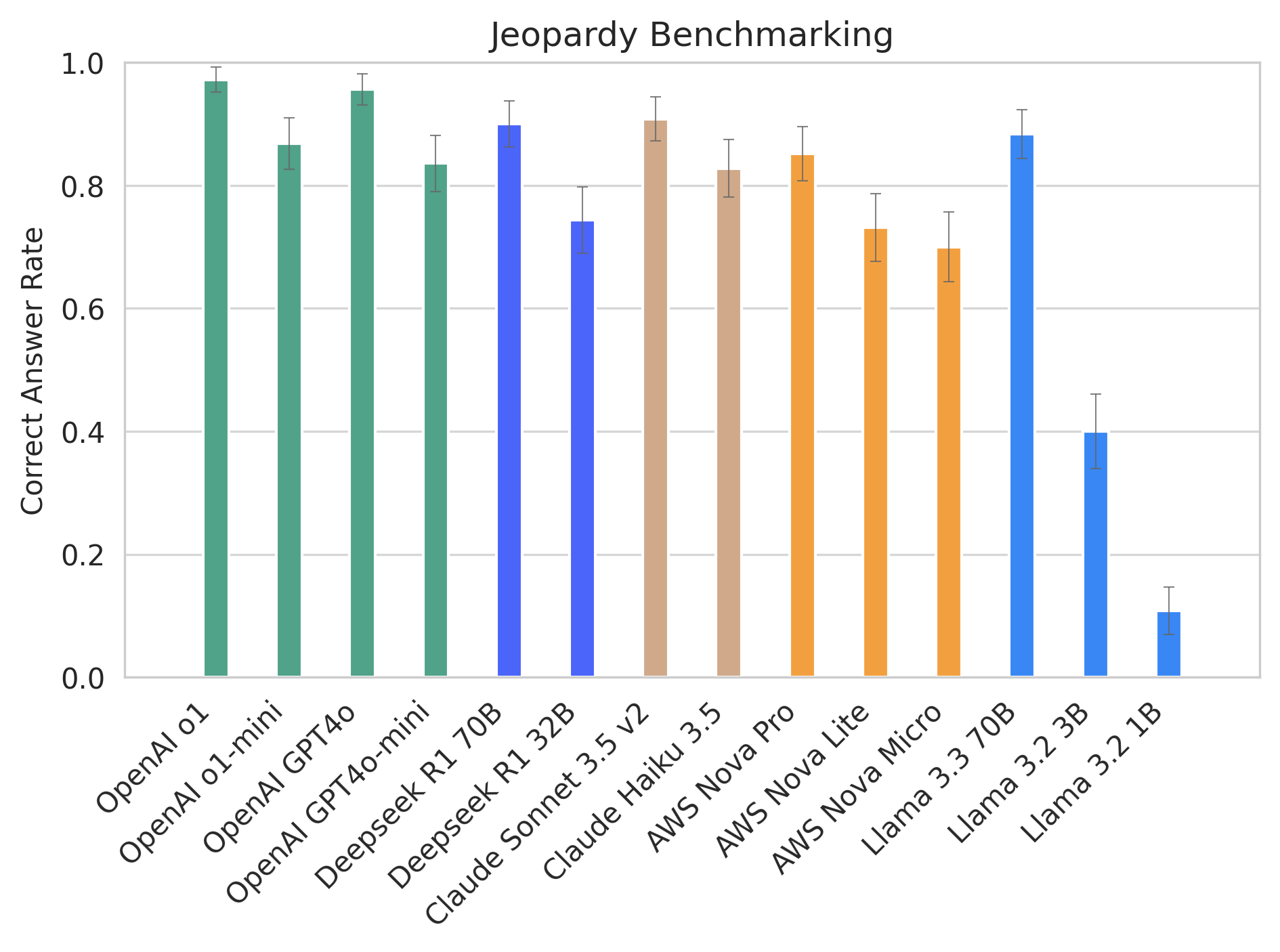
The benchmarking result is very consistent with our previous attempt:
- DeepSeek R1 70B is comparable and even slightly better than OpenAI o1-mini
- DeepSeek R1 32B is less performant than 70B
Besides inference quality, speed also matters. So we also compare how the 14 models perform in terms of inference speed.
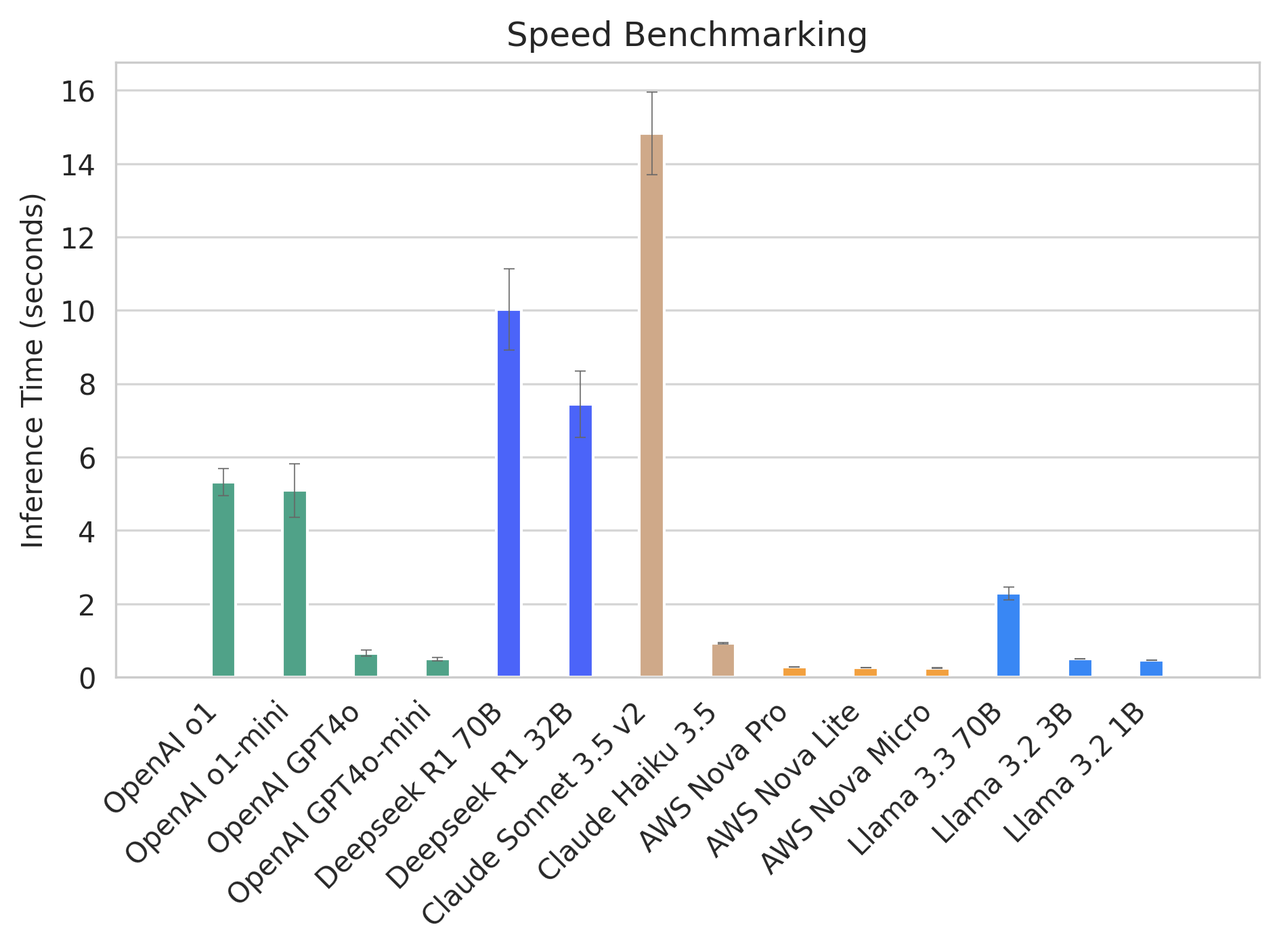
The speed of DeepSeek R1 70B is a bit faster than Claude Sonnet 3.5 v2, while delivering comparably accurate results. The smaller DeepSeek R1 32B is faster, but depending on your use case, the tradeoff might not be worth the speed up.
Reflections
Once I got the ml.p4d.24xlarge instance quota, setting up DeepSeek from Bedrock marketplace deployment was such a breeze. Given the size of the 70B model, I was expecting to wait a while for deployment to be done. But the model was ready within minutes.
And because I'm using Bedrock and the boto3 Python SDK, switching model is super easy. All I had to do was switch the model Id (sometimes model ARN or model endpoint). While the OpenAI models still lead the performance for the Jeopardy! questions, for different use cases, having the optionality of multiple models from Bedrock can be very helpful.
Clean Up
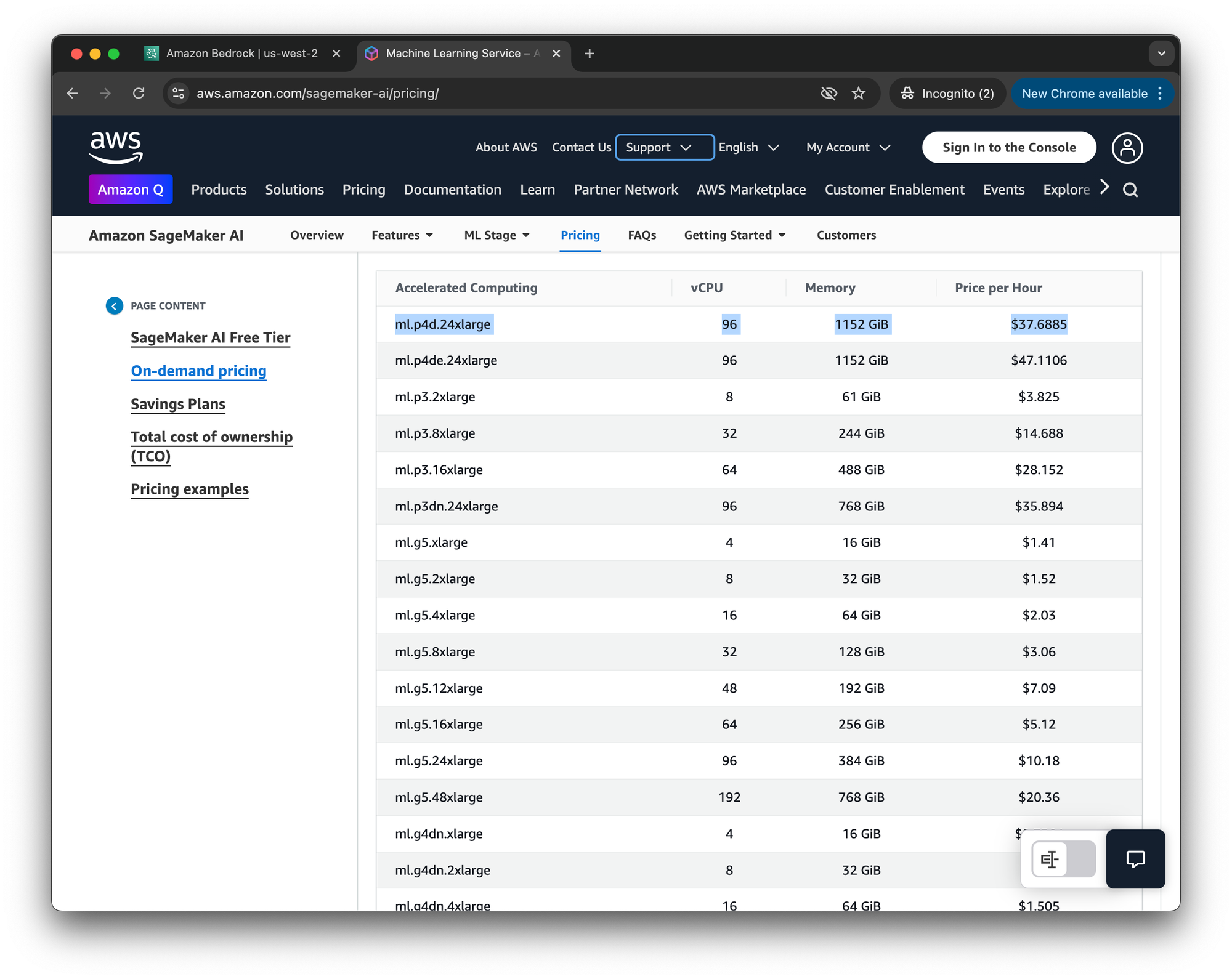
If you do try out Bedrock Marketplace Deployment, don't forget to turn off your instance after you are done! Before turning on an AWS resource, it's always a good idea to check out the pricing page. The ml.p4d.24xlarge instance is very powerful, and its price reflects that!